こんにちは、コンちゃんこと佐々木です。
秋田に競技プログラマーっているのか?とふと思うなどしています。
プログラマー自体、秋田に少ないような。
さて、競技プログラミングの大会「CODE THANKS FESTIVAL 2014 A日程」のオンサイトの懇親会では”書道コーディング”というコンテンツがありましてですね…
ちょいと書道したらchokudaiさん賞をいただいてしまったのですよ。
書道コーディングchokudai賞発表中#codefes pic.twitter.com/xSOyH1JfFP ? トイレ5個さん (@chako0407) 2014, 12月 7
その時に「この人にH問題(今回のコンテストの最難関問題)を解いてTwitterに流してもらおう」ということにされてしまったのです。
というわけで、あれから1ヶ月、解きました(投稿はとても遅くなってしまった)。
(冗談だったのかもしれませんが、わりと冗談分からない人間だったりするし、あとこういうのは使命感に燃える)
当記事の目次は、以下のとおりです。
満点解答コードを先に見たい方や、お急ぎの方は2-4をどうぞ。
参加記は→こちら!(写真大量につき重いかも,プログラミングできなくてもついていける)
1. CTF A日程 H問題の確認
2. 解説
2-1. まずは全探索を書こう
2-2. ローリングハッシュって何?何なの!?
2-3. 4乗オーダーにする
2-4. 結論と最終的な満点コード
3. おまけ:書道コーディングで書いたコードについて
この記事にある、私が書いたコードはコピー・改変等ご自由に、皆さんの責任のもとでどうぞー。
_____________________________________________________
1. CTF A日程 H問題の確認
H問題ページ→こちら
chokudaiさんによる解説スライド→こちら
y3eadgbeさんによる満点解答コード→こちら
ローリングハッシュについて述べられている他サイトさん→こちら とか こちら
※この記事は解説スライドとy3eadgbeさんのコードをあちこち引用しています。
解説スライドに書いてある問題概略をそのまま書くと…
・縦R行、横C列の各マスに文字列が書かれている。
・2*2以上の領域で、点対称な形になっているものの総数を求めよ。
・1<=R<=250
・1<=C<=250
あと特筆点は、制限時間が8秒と、普段の問題とは違うところ。
2. 解説
解説は、だんだん満点解法になるように解いていたので、その流れそのまま書きます。
全探索→ローリングハッシュ→4乗オーダー化 となります。
最後に結論と満点コードを載せます。
言語はC++(CっぽいコードにC++のSTLを入れた程度のもの)です。
2-1. まずは全探索を書こう
(ローリングハッシュを知らない前提です)
この項目の結論:文字列単位で普通に文字列処理する全探索は5乗オーダーでTLE、15点。
全てのパターン(切り出しデザイン候補の四角形)を試すコードを書こう!
…とは言いつつ、本番で同じこと思ってさっぱりコード書けなかった自分がいます…。
全探索は、forループが4重になります。
表形式だから2重ループ…じゃない!
解説スライドp45にありますが、左上座標と右下座標を、それぞれforループ2重で回します。
左上座標について、2次元表全探索、右上座標についても、2次元表全探索、掛け合わせて2*2=4重ループ。
ここまでのソースは以下のとおり。
include文などは省略。
#define FOR(i,a,b) for(int i=(a);i<(b);i++) // FOR(変数, aから, bまで(b含まず))
int solve(int R, int C, vector<string> &field){
int ans = 0;
FOR(HU_r, 0, field.size()){
FOR(HU_c, 0, C - 1){
FOR(MS_r, HU_r + 1, field.size()){
FOR(MS_c, HU_c + 1, field[HU_r].size()){
if (Check(HU_r, HU_c, MS_r, MS_c, field))
ans++;
}
}
}
}
return ans;
}
int main(){
fastIO;
int R = 0, C = 0;
string temp;
// 入力
cin >> R >> C;
vector<string> field;
field.reserve(R);
FOR(i, 0, R){
cin >> temp;
field.push_back(temp);
}
// 入力おわり
cout << solve(R, C, field) << endl;
return 0;
}
左上とか右下とか、英訳分からないのでHUとMS。_rは縦(行)。 _cは横(列)。
左上座標と右下座標が重なるパターンは答えになり得ない、MS座標はHU座標に一番近いパターンで_r、_cともにHU+1。
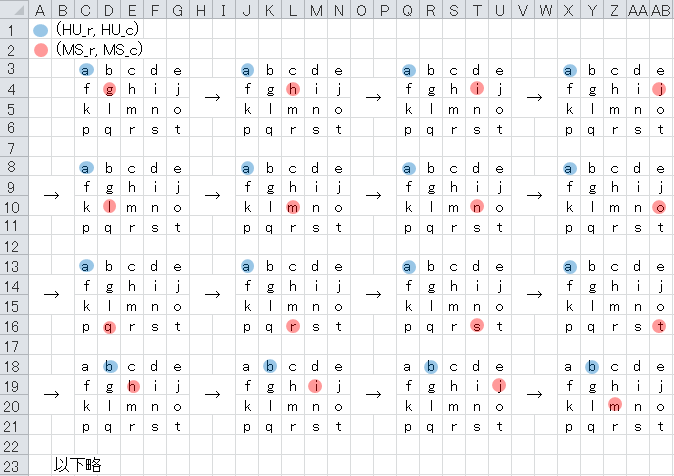
調査順番のイメージ。
青点と赤点で囲まれる四角形が、点対称かどうか。
左上座標(青点)と右下座標(赤点)が重なるパターンは、答えになり得ない。
さて、Check関数(9行目)には2点の座標を渡して、この座標で指定される四角形が点対称かどうかをチェックする処理をします。
C++は文字列型であるstringが存在するので、文字列単位で1行ずつ比較していこう!
(C言語だとstringがないので、文字単位。)
四角形の最上行の文字列と最下行の反転文字列が等しいか比較、次に最上行+1行目と最下行-1行目、次に…という感じ。
解説スライドp46にありますね。
反転文字列は、reverse()を使用します(<algorithm>に含まれます)。
戻り値はvoidです。 stringではないのでstring temp = reverse(a.begin(),a.end());とは書けません、注意。
文字列の比較は==でできます。 Javaだとダメです。 (たまにごっちゃになるよね!ねっ、なるよね!?)
計算量ですが、solve関数の4重ループで最悪だいたいR^2*C^2、Check関数のwhileループでiが最悪R/2、全体オーダーでO(R^3C^2)でしょうか。
RもCもMAX250なので250^5=9765億6250万です。
// 100^5=100億
コンテスト当日の会場生解説で、「AtCoderだと1億オーダーくらいがギリギリ(=2sec)」という話があった気がするので、とても8secには間に合いません。
(計算量の話は苦手でいつも大雑把にとらえています。logとか出るともっと分かりません。特に勉強していないからです。)
コードは以下のとおり。
// #define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <string>
#include <vector>
#include <map>
#include <set>
#include <stack>
#include <cmath>
#include <cstdlib>
#include <functional>
#include <locale>
#include <cctype>
#include <sstream>
using namespace std;
typedef long long LL;
typedef vector<int> VI;
typedef vector<VI> VVI;
typedef map<int, int> MAPII;
typedef vector<pair<int, int> > VPII;
typedef multimap<int, string, greater<int> > MuMIS;
#define MP make_pair
#define fastIO cin.tie(0); ios::sync_with_stdio(false);
#define FOR(i,a,b) for(int i=(a);i<(b);i++)
//for gcc (未test)
// #define FOREACH_IT(it,c) for(typeof(c)::iterator it=(c).begin(); it!=(c).end(); ++it)
//for Visual Studio
#define foreach_it(type,it,c) for(type::iterator it=c.begin(),c_end=c.end();it!=c_end;++it)
// 未test
#define DUMP_VVI(b) FOR(i,0,b.size()){FOR(j,0,b[i].size())printf("%d ",b[i][j]);puts("");}
// ------------------- include, typedef, define END. -------------------
bool Check(int HU_r, int HU_c, int MS_r, int MS_c, vector<string> &field){
bool ret = false;
int h = MS_r - HU_r;
int w = MS_c - HU_c;
int i=0;
string temp1,temp2;
while(HU_r+i <= MS_r-i){
temp1 = field[HU_r+i].substr(HU_c, w+1);
temp2 = field[MS_r-i].substr(HU_c, w+1);
reverse(temp2.begin(), temp2.end());
if(temp1 != temp2){
return false;
}
i++;
}
ret = true;
return ret;
}
int solve(int R, int C, vector<string> &field){
int ans = 0;
FOR(HU_r, 0, field.size()){
FOR(HU_c, 0, C - 1){
FOR(MS_r, HU_r + 1, field.size()){
FOR(MS_c, HU_c + 1, field[HU_r].size()){
if (Check(HU_r, HU_c, MS_r, MS_c, field))
ans++;
}
}
}
}
return ans;
}
int main(){
fastIO;
int R = 0, C = 0;
string temp;
// 入力
cin >> R >> C;
vector<string> field;
field.reserve(R);
FOR(i, 0, R){
cin >> temp;
field.push_back(temp);
}
// 入力おわり
cout << solve(R, C, field) << endl;
return 0;
}
提出結果は、部分点15点のTLEです→こちら!
普通に文字列処理すると、遅いのです。
2-2. ローリングハッシュって何?何なの!?
この項目の結論:文字列を数値に変換して比較すると速い。5乗オーダーで変わらないがTLEの45点get。
H問題、ローリングハッシュ。初耳です。 — コンちゃん@ctfH問題解説執筆中 (@conchan_akita) 2014, 12月 7
文字列比較を高速化しましょう。
解説p47に”ローリングハッシュ”なる文字列が存在します。
会場生解説で”ローリングハッシュ”と聞いたとき、皆さん分からなさそうで安心しました(自分も分からないので)。
ローリングハッシュ、なんか強そう #codefes — Genki @ 就活戦士 (@GenkiSugimotoJP) 2014, 12月 7
ローリングハッシュってなんですか!? #codefes — 68pF (@686868ah) 2014, 12月 7
ローリングハッシュなんて初めて聞いた #codefes — とまと (@poe03) 2014, 12月 7
必殺技みたいな名前(ローリングハッシュ) #codefes — もっさんさん (@moxtsuan) 2014, 12月 7
rolling hash, 蟻本に載っているんだよね #codefes — koba (@kobae964) 2014, 12月 7
ローリングハッシュ? #codefes — kado@94 (@kado_m) 2014, 12月 7
H 問題の解説、何を言っているのかさっぱりだった… #codefes — たけ (@ww24) 2014, 12月 7
ローリングハッシュを使うと、文字列を、数値の四則演算によってハッシュ値に置き換えることができます。
文字を扱うより数値の四則演算の方が速いようなので、ぜひ覚えましょう。
●ローリングハッシュ
文字列を、ハッシュ関数によってハッシュ値にする。
2つのハッシュ値が等しいということは、その2つの文字列は等しいといえる。
(そう言えるようなハッシュ関数を用いる)
H問題では、ローリングハッシュと呼ばれるハッシュ関数を使う。
(”ローリングハッシュ”が、ハッシュ関数名なのかこの手法の名前かはよく分からない) ←たぶんハッシュ関数名。
ローリングハッシュは、文字列の検索(ラビン-カープ文字列探索アルゴリズム)に用いられ、文字列のハッシュ値を高速に求めることができる。
以下のようにハッシュをとる。 (解説スライドとちょっと違うので注意)
// 文字列abcのハッシュ値Hを求める string str = "abc"; long long int base = 1000000009; long long int H = str[0] * base^2 + str[1] * base^1 + str[2] * base^0; // str[0] * base^2 というのは、 (aの文字コード) * (baseの2乗) を意味する。
一般化すると、ハッシュをとりたい文字列をstr、文字列の長さをmとして
H = str[0] * base^(m-1)
+ str[1] * base^(m-2)
+ str[2] * base^(m-3)
+ ...
+ str[m-1] * base^0;
です。
日本語で書くと、
文字列は先頭文字から1文字ずつ文字コードを見ていき、
baseは末尾項が0乗、前項が1乗…+1ずつ加算
、です。
<このハッシュ関数の便利なところ>
・後ろに1文字追加したときに、前までのハッシュ値を使用して高速にハッシュ値を求められる(累積和っぽい考え方だなーって思った)
(例)
abcのハッシュがすでに求まっている(Habcとする)。
後ろにdを追加した文字列abcdのハッシュHabcdは
string str = abcd; Habcd = Habc * base + d;
また、文字列abcdについて、Habcを使ってHbcd(1個分ずらした、同じ長さの文字列)を高速に求められる。
string str = abcd;
Hbcd = Habc - a * base^(ハッシュを求めたい文字列の文字数-1) + d;
= Habc - a * base^2 + d;
→これは、文字列abcdefghijklmno…に対し、最初にabcを見て、次にbcdを見て、その次はcdeを見て…というときに役立つ。
・「先頭からその文字列までのハッシュ値」を事前計算して配列に格納しておくと、部分文字列のハッシュ値はその配列から求まる。
→これは、文字列abcdefghijklmno…に対し、最初にbcを見て、次にcdefを見て、次にjklmnoを見て…というように変則的に見るときに高速にハッシュ値を求められる。
// 先頭からその文字列までのハッシュ値を格納する、要素数10000、初期値0の配列
// hash[i]には,先頭文字からi(0<=i<=(strの長さ-1))番目の文字までの文字列のハッシュ値が入っている.
vector<long long> hash(10000,0);
string str = abcdefghijk...;
// 事前計算
// hash[0] = Ha
// hash[1] = Hab
// hash[2] = Habc
// ...以下略
hash[0] = str[0];
for(int i=1; i<str.length(); i++)
hash[i] = hash[i-1] * base + str[i];
(例) Hbc = Habc - Ha * base^(ハッシュを求めたい文字列の文字数)
= hash[2] - hash[0] * base^2; // ← 事前計算しておいたhash配列から求められる!
(例2) Hcdef = Habcdef - Hab * base^(ハッシュを求めたい文字列の文字数)
= hash[5] - hash[1] * base^4;
// Hcdef = c * base^3 + d * base^2 + e * base^1 + f * base^0; で求めたものとちゃんと一致しますよ!
// ハッシュを求めたい文字列の長さによらず、hash[?]-hash[?]*base^?で求められる!式短い!
// 日本語で書くと
// string str = abcdefghijklmnop で Hghikj を求めたいときを例に
// 事前にhash配列を用意する
// hash[0] = aのハッシュ = aの文字コード
// hash[1] = abのハッシュ
// = 1つ前のhash * base + 追加文字
// = hash[0] * base + b
// hash[2] = abcのハッシュ
// = 1つ前のhash * base + 追加文字
// = hash[1] * base + c
// ...
// hash[15] = abcdefghijklmnopのハッシュ
// = hash[14] * base + p
// 用意完了しましたー。
// Hghijk = 先頭からkまでのhash - 先頭からgの1個前までのhash * (base^ハッシュを求めたい文字列の文字数)
// = hash[10] - hash[5] * base^5;
<ポイント>
全ての部分文字列のハッシュ値を持つわけではない。
先頭から各文字までのハッシュ値を保持して、必要な時にそこから計算する。
baseに大きい素数を持ってくることで、modを取らずともokになります。 (実はなぜokなのかよく分かっていないけど、base=10なんかよりずっとハッシュ衝突起こらなさそうな感じがするよ!) baseは巨大な値なので、累乗して桁あふれが普通に起きてマイナスの値になるけど、プログラムは停止しないのでok…。
modを取るというのは、めちゃくちゃ巨大な数をある値未満に収める(例:どんな巨大数もmod10取ると10未満の数になる)ことです(セキュリティ・暗号分野で頻出)。
baseをunsigned long long 型(64bit)にして、ハッシュ値格納する変数や配列もunsigned long long 型にしてあげると、桁あふれが起きようと64bitに収まる = mod2^64することと同義。
baseの累乗は、事前計算します。
前の値を利用して求めて配列に入れておきます。つまりbaseのn乗は
base[n] = base[n-1] * base;
で求めておきます。
(いちいちbase[n] = pow(base,n); なんてやると、遅い!)
ハッシュは、逆文字列分も用意しましょう。
hash1[255][255]と、hash2_rev[255][255]。
hash1[a][b]には、a行目における、先頭列からb列目までの文字列、のハッシュ値を格納。
hash2_rev[a][b]には、a行目における、末尾列からb列目までの(末尾側から先頭方向に見た)文字列、のハッシュ値を格納。
※a,bは0スタート。

ハッシュのとり方イメージ。
どこまでのハッシュをどのように格納するか、については、y3eadgbeさんによる満点解答コードとちょいと違いますので注意ねー。
2-1からガラッと変わったコードは、以下のとおり。
// #define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <string>
#include <vector>
#include <map>
#include <set>
#include <stack>
#include <cmath>
#include <cstdlib>
#include <functional>
#include <locale>
#include <cctype>
#include <sstream>
using namespace std;
typedef long long LL;
typedef vector<int> VI;
typedef vector<VI> VVI;
typedef map<int, int> MAPII;
typedef vector<pair<int, int> > VPII;
typedef multimap<int, string, greater<int> > MuMIS;
#define MP make_pair
#define fastIO cin.tie(0); ios::sync_with_stdio(false);
#define FOR(i,a,b) for(int i=(a);i<(b);i++)
//for gcc (未test)
// #define FOREACH_IT(it,c) for(typeof(c)::iterator it=(c).begin(); it!=(c).end(); ++it)
//for Visual Studio
#define foreach_it(type,it,c) for(type::iterator it=c.begin(),c_end=c.end();it!=c_end;++it)
// 未test
#define DUMP_VVI(b) FOR(i,0,b.size()){FOR(j,0,b[i].size())printf("%d ",b[i][j]);puts("");}
// ------------------- include, typedef, define END. -------------------
LL base = 1000000009;
LL base_pow[255]; // C<=250なので余裕持って255. base_pow[i] = base^i.
LL hash1[255][255] = {};
LL hash2_rev[255][255] = {};
LL Get_hash1(int HU_r, int HU_c, int MS_r, int MS_c){
// MS_rは使い道ない
return hash1[HU_r][MS_c] - hash1[HU_r][HU_c-1] * base_pow[MS_c-HU_c+1];
}
LL Get_hash2(int HU_r, int HU_c, int MS_r, int MS_c){
// HU_rは使い道ない
return hash2_rev[MS_r][HU_c] - hash2_rev[MS_r][MS_c+1] * base_pow[MS_c-HU_c+1];
}
bool Check2(int HU_r, int HU_c, int MS_r, int MS_c){
bool ret = true;
int i=0;
while(HU_r+i <= MS_r-i){
LL nowHash1 = Get_hash1(HU_r+i,HU_c,MS_r-i,MS_c);
LL nowHash2 = Get_hash2(HU_r+i,HU_c,MS_r-i,MS_c);
if(nowHash1 != nowHash2){
return false;
}
i++;
}
return ret;
}
int solve(int R, int C, vector<string> &field){
int ans = 0;
// HU : 左上 MS : 右下
FOR(HU_r, 0, field.size()){
FOR(HU_c, 0, C - 1){
FOR(MS_r, HU_r + 1, field.size()){
FOR(MS_c, HU_c + 1, field[HU_r].size()){
if (Check2(HU_r, HU_c, MS_r, MS_c))
ans++;
}
}
}
}
return ans;
}
// http://code-thanks-festival-2014-a-open.contest.atcoder.jp/submissions/294369
// 上記URL先コードを参考にしています.
int main(){
fastIO;
int R = 0, C = 0;
string temp;
// 入力
cin >> R >> C;
vector<string> field;
field.reserve(R);
FOR(i, 0, R){
cin >> temp;
field.push_back(temp);
}
// 入力おわり
// ハッシュ計算用
base_pow[0]=1;
FOR(i,0,C){
base_pow[i+1] = base_pow[i] * base;
}
FOR(i,0,R){
FOR(j,0,C){
if(j==0) hash1[i][j] = 0 + field[i][j];
else hash1[i][j] = hash1[i][j-1] * base + field[i][j];
}
for(int j=C-1; j>=0; j--){
hash2_rev[i][j] = hash2_rev[i][j+1] * base + field[i][j];
}
}
cout << solve(R, C, field) << endl;
return 0;
}
提出結果はこちらのとおり、45点TLE。
ローリングハッシュしても満点じゃないなんて…。
2-3.4乗オーダーにする
Check2関数のwhileループ中では、上行から順に見ています。
solveのfor4重ループの中にも、上行から見ているものがあるので、なんかダブっている感あるー。
C方向に2重、R方向にも2重、の4重で何とかならないかな?
ここで、探索方法を変えます。
ある四角形の上行から順に見ていたのを、その四角形の中央行から見るようにします。
左上座標と右下座標の話をしていたあの頃は忘れて、for2重ループで先頭文字のある列と末尾文字のある列を指定、残り2重ループで中央行と、中央行からの距離を指定します。
ある四角形が点対称なら、その中にある小さい(列そのままで行だけ最上行と最下行カットの)四角形も点対称です。
逆に言うなら、小さい四角形からチェックしていき、点対称だったらans++、点対称じゃなくなったら、チェックをやめて、中央行(3重ループ目)をずらします。
この事実を利用すると、つまり4重ループ目内で新たに追加された外側2行だけ検査すればokってことなので、中に含まれる四角形の検査(=Check2関数でやっていたこと)を省けます。

探索順番イメージ。
実際には探索2つ目の四角形fgの時点で点対称ではなく、よって次の四角形abfgklは点対称にはなり得ないのでcontinue文で探索飛ばしたり。
コードは以下。
// #define _CRT_SECURE_NO_WARNINGS
// #define _USE_MATH_DEFINES
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <string>
#include <vector>
#include <map>
#include <set>
#include <stack>
#include <cmath>
#include <cstdlib>
#include <functional>
#include <locale>
#include <cctype>
#include <sstream>
using namespace std;
typedef long long LL;
typedef vector<int> VI;
typedef vector<VI> VVI;
typedef map<int, int> MAPII;
typedef multimap<int, char, greater<int> > MuMAPIC;
typedef vector<pair<int, int> > VPII;
typedef multimap<int, string, greater<int> > MuMIS;
#define MP make_pair
#define fastIO cin.tie(0); ios::sync_with_stdio(false);
#define FOR(i,a,b) for(int i=(a);i<(b);i++)
#define foreach_it(type,it,c) for(type::iterator it=c.begin(),c_end=c.end();it!=c_end;++it)
#define DUMP_VVI(b) FOR(i,0,b.size()){FOR(j,0,b[i].size())printf("%d ",b[i][j]);puts("");}
// 入力をpush_back(d)やarray[d]に使う時に1行で書ける
// int INPUT_INT() {int d;cin>>d;return d;}
template<class T>T IN(){T d;cin>>d;return d;}
// -------------------- include, typedef, define, template END. --------------------
LL base = 1000000009;
LL base_pow[255]; // C<=250なので余裕持って255. base_pow[i] = base^i.
LL hash1[255][255] = {};
LL hash2_rev[255][255] = {}; // reverse hash.
LL inline Get_hash1(int r, int HU_c, int MS_c){
// r = HU_r. MS_rは使い道ない
return hash1[r][MS_c] - hash1[r][HU_c-1] * base_pow[MS_c-HU_c+1];
}
LL inline Get_hash2(int r, int HU_c, int MS_c){
// r = MS_r. HU_rは使い道ない
return hash2_rev[r][HU_c] - hash2_rev[r][MS_c+1] * base_pow[MS_c-HU_c+1];
}
int inline solve(int R, int C){
int ans=0;
// HU : 左上, MS : 右下, dis : distance from the center line.
FOR(HU_c,0,C-1){
FOR(MS_c,HU_c+1,C){
// 高さが奇数(1,3,5,...)の四角形
FOR(i,0,R){
// 中央1行チェック
if(Get_hash1(i,HU_c,MS_c) != Get_hash2(i,HU_c,MS_c))
continue; // 次のiへ.
for(int dis=1; i-dis>=0, i+dis<R; dis++){
// 今見る四角形(最上行i-dis, 最下行i+dis)が, fieldに収まっているなら実行.
if(Get_hash1(i-dis,HU_c,MS_c) == Get_hash2(i+dis,HU_c,MS_c))
ans++;
else
break;
}
}
// 高さが偶数(2,4,6,...)の四角形
FOR(i,0,R){
for(int dis=1; i-dis +1 >=0, i+dis<R; dis++){
// 今見る四角形(最上行i-dis+1, 最下行i+dis)が, fieldに収まっているなら実行.
if(Get_hash1(i-dis +1 ,HU_c,MS_c) == Get_hash2(i+dis,HU_c,MS_c))
ans++;
else
break;
}
}
}
}
return ans;
}
// 以下のURL先のコードに大変お世話になりました.
// http://code-thanks-festival-2014-a-open.contest.atcoder.jp/submissions/294369
// 解法:4重ループにする,ローリングハッシュを書く.
int main(){
fastIO;
int R = 0, C = 0;
cin >> R >> C;
vector<string> field;
field.reserve(R);
FOR(i,0,R)
field.push_back(IN<string>());
base_pow[0]=1;
FOR(i,0,C)
base_pow[i+1] = base_pow[i] * base;
FOR(i,0,R){
FOR(j,0,C){
if(j-1<0) hash1[i][j] = 0 + field[i][j];
else hash1[i][j] = hash1[i][j-1] * base + field[i][j];
}
for(int j=C-1; j>=0; j--){
hash2_rev[i][j] = hash2_rev[i][j+1] * base + field[i][j];
}
}
cout << solve(R, C) << endl;
return 0;
}
提出結果は、100点AC。→こちら!
2014年中に解けて良かったー!
(URLにopenが含まれない、オンサイト専用サイトでも同じもの提出しました、H問題ACまだ自分だけなので、オンサイト参加者も提出しよう→こちら!)
2-4. 結論と最終的な満点コード
結論:オーダーが巨大で制限時間に間に合わなさそうな文字列検索(比較)は、ローリングハッシュを書こう。文字列検索系アルゴリズムの中では(理論さえ理解すれば)実装が楽で応用範囲も広めかな。
最終的なコードは、関数をインライン展開しています。
こっちの方が、ちょっとだけ速かったので。
(2-3のコードは5441ms、2-4のコードは4707ms。)
コードは以下のとおりです。提出結果は→こちら!
// #define _CRT_SECURE_NO_WARNINGS
// #define _USE_MATH_DEFINES
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <string>
#include <vector>
#include <map>
#include <set>
#include <stack>
#include <cmath>
#include <cstdlib>
#include <functional>
#include <locale>
#include <cctype>
#include <sstream>
using namespace std;
typedef long long LL;
typedef vector<int> VI;
typedef vector<VI> VVI;
typedef map<int, int> MAPII;
typedef multimap<int, char, greater<int> > MuMAPIC;
typedef vector<pair<int, int> > VPII;
typedef multimap<int, string, greater<int> > MuMIS;
#define MP make_pair
#define fastIO cin.tie(0); ios::sync_with_stdio(false);
#define FOR(i,a,b) for(int i=(a);i<(b);i++)
#define foreach_it(type,it,c) for(type::iterator it=c.begin(),c_end=c.end();it!=c_end;++it)
#define DUMP_VVI(b) FOR(i,0,b.size()){FOR(j,0,b[i].size())printf("%d ",b[i][j]);puts("");}
// 入力をpush_back(d)やarray[d]に使う時に1行で書ける
// int INPUT_INT() {int d;cin>>d;return d;}
template<class T>T IN(){T d;cin>>d;return d;}
// -------------------- include, typedef, define, template END. --------------------
LL base = 1000000009;
LL base_pow[255]; // C<=250なので余裕持って255. base_pow[i] = base^i.
LL hash1[255][255] = {};
LL hash2_rev[255][255] = {}; // reverse hash.
LL inline Get_hash1(int r, int HU_c, int MS_c){
// r = HU_r. MS_rは使い道ない
return hash1[r][MS_c] - hash1[r][HU_c-1] * base_pow[MS_c-HU_c+1];
}
LL inline Get_hash2(int r, int HU_c, int MS_c){
// r = MS_r. HU_rは使い道ない
return hash2_rev[r][HU_c] - hash2_rev[r][MS_c+1] * base_pow[MS_c-HU_c+1];
}
int inline solve(int R, int C){
int ans=0;
// HU : 左上, MS : 右下, dis : distance from the center line.
FOR(HU_c,0,C-1){
FOR(MS_c,HU_c+1,C){
// 高さが奇数(1,3,5,...)の四角形
FOR(i,0,R){
// 中央1行チェック
if(Get_hash1(i,HU_c,MS_c) != Get_hash2(i,HU_c,MS_c))
continue; // 次のiへ.
for(int dis=1; i-dis>=0, i+dis<R; dis++){
// 今見る四角形(最上行i-dis, 最下行i+dis)が, fieldに収まっているなら実行.
if(Get_hash1(i-dis,HU_c,MS_c) == Get_hash2(i+dis,HU_c,MS_c))
ans++;
else
break;
}
}
// 高さが偶数(2,4,6,...)の四角形
FOR(i,0,R){
for(int dis=1; i-dis +1 >=0, i+dis<R; dis++){
// 今見る四角形(最上行i-dis+1, 最下行i+dis)が, fieldに収まっているなら実行.
if(Get_hash1(i-dis +1 ,HU_c,MS_c) == Get_hash2(i+dis,HU_c,MS_c))
ans++;
else
break;
}
}
}
}
return ans;
}
// 以下のURL先のコードに大変お世話になりました.
// http://code-thanks-festival-2014-a-open.contest.atcoder.jp/submissions/294369
// 解法:4重ループにする,ローリングハッシュを書く.
int main(){
fastIO;
int R = 0, C = 0;
cin >> R >> C;
vector<string> field;
field.reserve(R);
FOR(i,0,R)
field.push_back(IN<string>());
base_pow[0]=1;
FOR(i,0,C)
base_pow[i+1] = base_pow[i] * base;
FOR(i,0,R){
FOR(j,0,C){
if(j-1<0) hash1[i][j] = 0 + field[i][j];
else hash1[i][j] = hash1[i][j-1] * base + field[i][j];
}
for(int j=C-1; j>=0; j--){
hash2_rev[i][j] = hash2_rev[i][j+1] * base + field[i][j];
}
}
cout << solve(R, C) << endl;
return 0;
}
3.おまけ:書道コーディングで書いたコードについて
懇親会中にわざわざカバンから競プロ用ファイルを取り出して、大量のinclude文などを書道(書写)しました。
途中で、「あっこれ全部はまらない」って気づいて部分省略していたり。
include文(typedefやdefineやtemplate含む、以下「include文」)は、コード書き始めに丸々コピーして貼り付けます。
include文が足りないのでエラー出た!といった事態を避けるために、また、手早くコードを書くために用います。
あと、CODE THANKS FESTIVAL A日程オンサイトは2014年12月7日でしたけど、この大量include文を書き始めたのは実は約1ヶ月前だったり。
他の方のコードを見て大量のinclude文などがあったので、真似してみたのです。
最初は真似でしたけど、AOJで簡単な問題を解きながら、自分が分かりやすいように改造しています。
(fastIOなんて、他に#define化している人を見たことがないよ、自作だよ。)
#include系列は、「AOJで使ったら追加する」スタイル。
つまり、全部1回以上使ったことがあるのだー。
以下にコードを記載しておくので、各自使いやすいようにお使いくださいませー。
// #define _CRT_SECURE_NO_WARNINGS
// #define _USE_MATH_DEFINES
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <string>
#include <vector>
#include <map>
#include <set>
#include <stack>
#include <cmath>
#include <cstdlib>
#include <functional>
#include <locale>
#include <cctype>
#include <sstream>
using namespace std;
typedef long long LL;
typedef vector<int> VI;
typedef vector<VI> VVI;
typedef map<int, int> MAPII;
typedef multimap<int, char, greater<int> > MuMAPIC;
typedef vector<pair<int, int> > VPII;
typedef multimap<int, string, greater<int> > MuMIS;
#define MP make_pair
#define fastIO cin.tie(0); ios::sync_with_stdio(false);
#define FOR(i,a,b) for(int i=(a);i<(b);i++)
//for gcc (未test)
// #define FOREACH_IT(it,c) for(typeof(c)::iterator it=(c).begin(); it!=(c).end(); ++it)
//for Visual Studio
#define foreach_it(type,it,c) for(type::iterator it=c.begin(),c_end=c.end();it!=c_end;++it)
#define DUMP_VVI(b) FOR(i,0,b.size()){FOR(j,0,b[i].size())printf("%d ",b[i][j]);puts("");}
template<class T>T IN(){T d;cin>>d;return d;}
// -------------------- include, typedef, define, template END. --------------------
__________________________________________________
・4乗オーダーの文字列処理だと?
4乗オーダーで、ローリングハッシュ使わず文字列処理で頑張ってもTLE45点でした。→こちら!
・いただいたギフト券の使い道
chokudaiさんの本を買うために使う予定。H問題解説書いてから使おうと、とっておいたのさ!
・学科HP
研究室の毎週の進捗発表で、「競技プロコンオンサイト行った」「また行った」などと報告したら、学科HPに記事ができました(書きました)。
超短く書いて、とのことで、書きたいこと全然書けなかったぜ…。
・卒論
OSの研究をしていましたが、就活終わらず論文にできるものが何もなく、ラビン-カープ文字列探索アルゴリズムについてを卒論にしてしまった…。
・記事作成に手間取った
本記事の作成は、改行がうまくいかず手間取りました。対処法忘れないうちにメモしました → WordPressにTwitterを貼り付けると改行が消滅する問題への対処法
___________________________________________________
chokudaiさんの解説スライドを除けば、A日程H問題解説記事は世界初かも?
それでは皆さん、より強くより楽しい競技プログラマーライフを目指しましょう!